IoT installations are often designed to accommodate AI applications with different objectives in later stages of expansion. But many companies fail to derive enough added value from their AI projects. Collaboration with specialists protects against falling into traps like survivorship bias in data analysis.
During the Second World War, US Navy engineers were working on how to reduce the number of their own fighter planes being shot down and thus increase the survival rate of the crews. Armouring the entire aircraft was out of the question for weight reasons. The designers decided to reinforce the aircraft with armour plates where the most frequent bullet holes were to be found. This did not prove successful. Since the additional armouring itself worked, the designers suspected an error in their database. They therefore commissioned Adam Wald, a Romanian-American mathematician. He concluded from the data that it was not the areas with the most bullet holes that had to be reinforced, but the fuselage sections with the fewest bullet holes. Aircraft that had been hit there had disproportionately often not made it back to base and thus evaded the data analysis. The success proved the mathematician right.
Interdisciplinary teams
Adam Wald's example is regarded by many as proof that two expert profiles are needed for successful data-based projects: Industry or product specialists who recognise and solve the need for optimisation, and data scientists who know how to handle data. Yet even today, many data science projects do not get beyond the concept phase or are stopped during implementation due to a lack of success, observes Frank Müller in his function as Director Data Science at infoteam Software. This applies to projects with comparatively simple data analyses and visualisations as well as sophisticated AI solutions. "The first thing companies often ask us is whether we can already demonstrate project successes in their industry and, at best, in exactly their special discipline," says Müller. Yet data is always data - regardless of the industry in which it is collected. Many completely different-sounding requirements from very different industries can be solved with the same tools and technologies. However, these connections are hardly recognisable for non-data scientists, Müller explains.
Data scientists in the team
Two examples support this view: the first concerns the failure prediction for device components based on temperature sensor data. The second describes the software that pre-sorts the content of telephone error messages from customers and offers the responsible service technician comparable messages including a solution path from the past. Both tasks are industry-independent, sound completely different and yet can be reduced to a similar data structure. In both cases, time series are a decisive factor, because it is a matter of finding patterns in temporal sequences. Therefore, in both examples, technologies are used as a solution approach, as they are also used in 'Natural Language Processing' (NLP), i.e. in computational linguistics. The real difference and the subtleties of both tasks lie in reacting to the individuality of the data with different tools from the portfolio of statistical methods and machine learning.
Intersections of AI
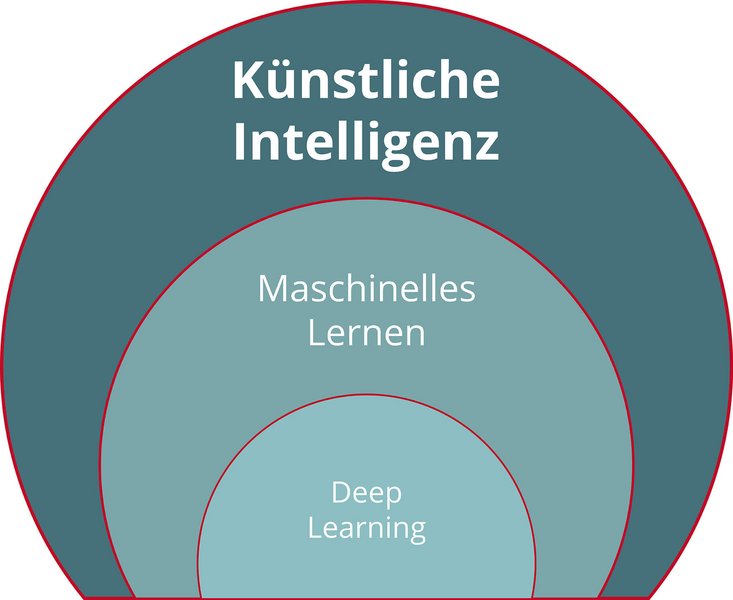
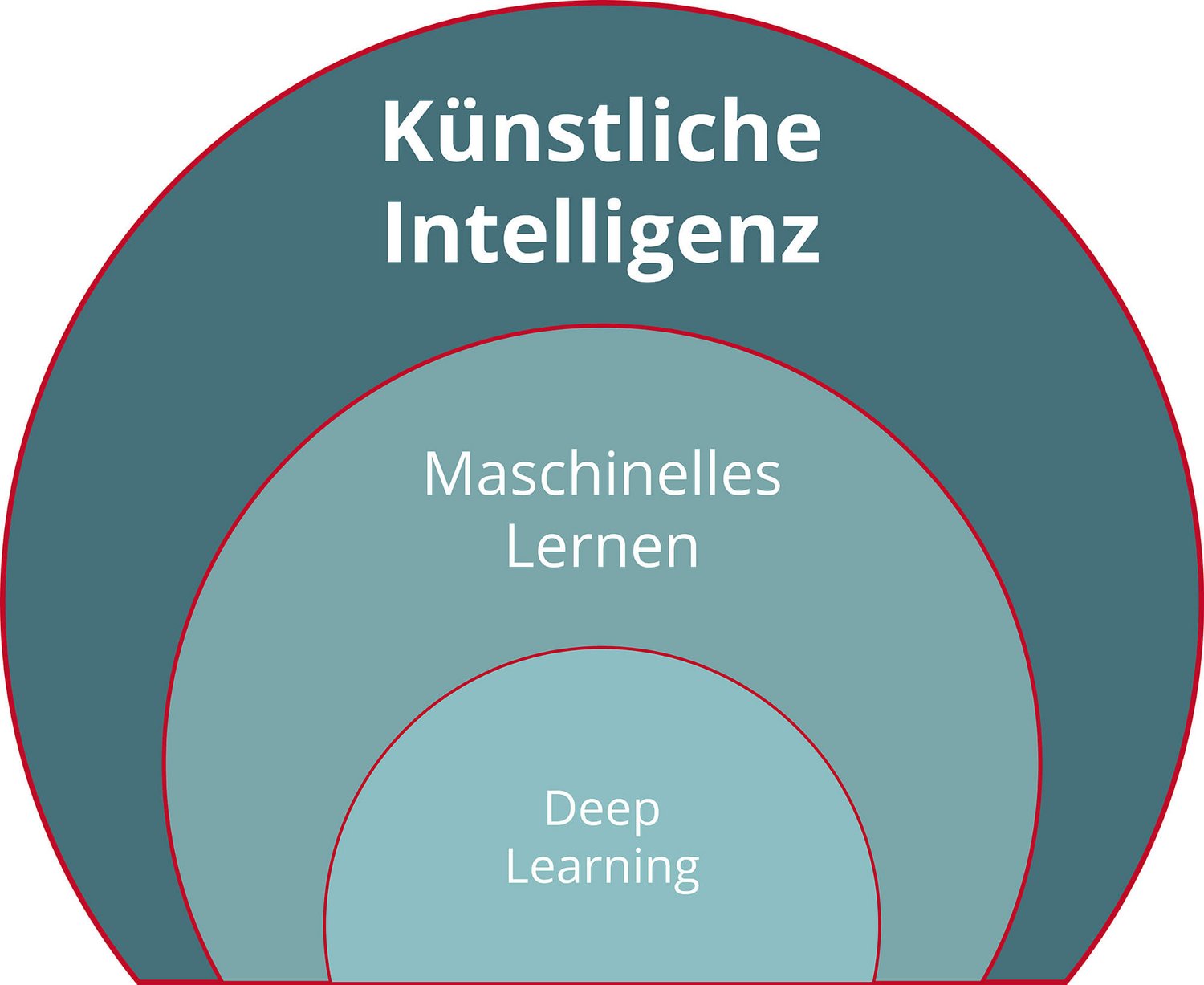
The term 'artificial intelligence', which is often used in this context, is not universally defined, but merely describes hardware or software that imitates human behaviour in a certain way. Whether this behaviour is based on classically programmed if-then rules or on more complex modelling makes no difference. A subset of artificial intelligence is data-based machine learning, which includes deep learning with deep neural networks. It falls into three categories:
Supervised learning - This includes input-output pairs, e.g. the type of use of a machine (input) and the corresponding temperature development of a machine component (output). The AI observes over a longer period of time how the type of use and temperature development are related and is then able to predict temperature developments and recognise conspicuous temperature deviations based on this.
Unsupervised learning - Here, an AI examines a data set without prior knowledge to see whether correlations are recognisable. For example, such an AI could sort a motley pile of triangles, squares and circles into different clusters (number of corners, size, colour, etc.). An AI of this kind is exciting for data that a human can no longer analyse due to its complexity.
Reinforcement learning - The AI model trains itself and is rewarded if it is successful. A self-learning AI for the game Four Wins tries different approaches and learns from winning and losing. This works in interaction with a human and in some constellations also in training against itself. In this way, AI can optimise the power consumption of machinery, for example.
Data science project flow
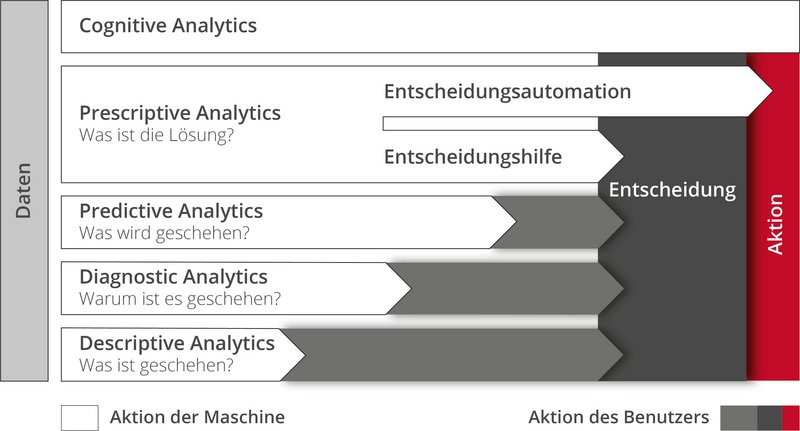
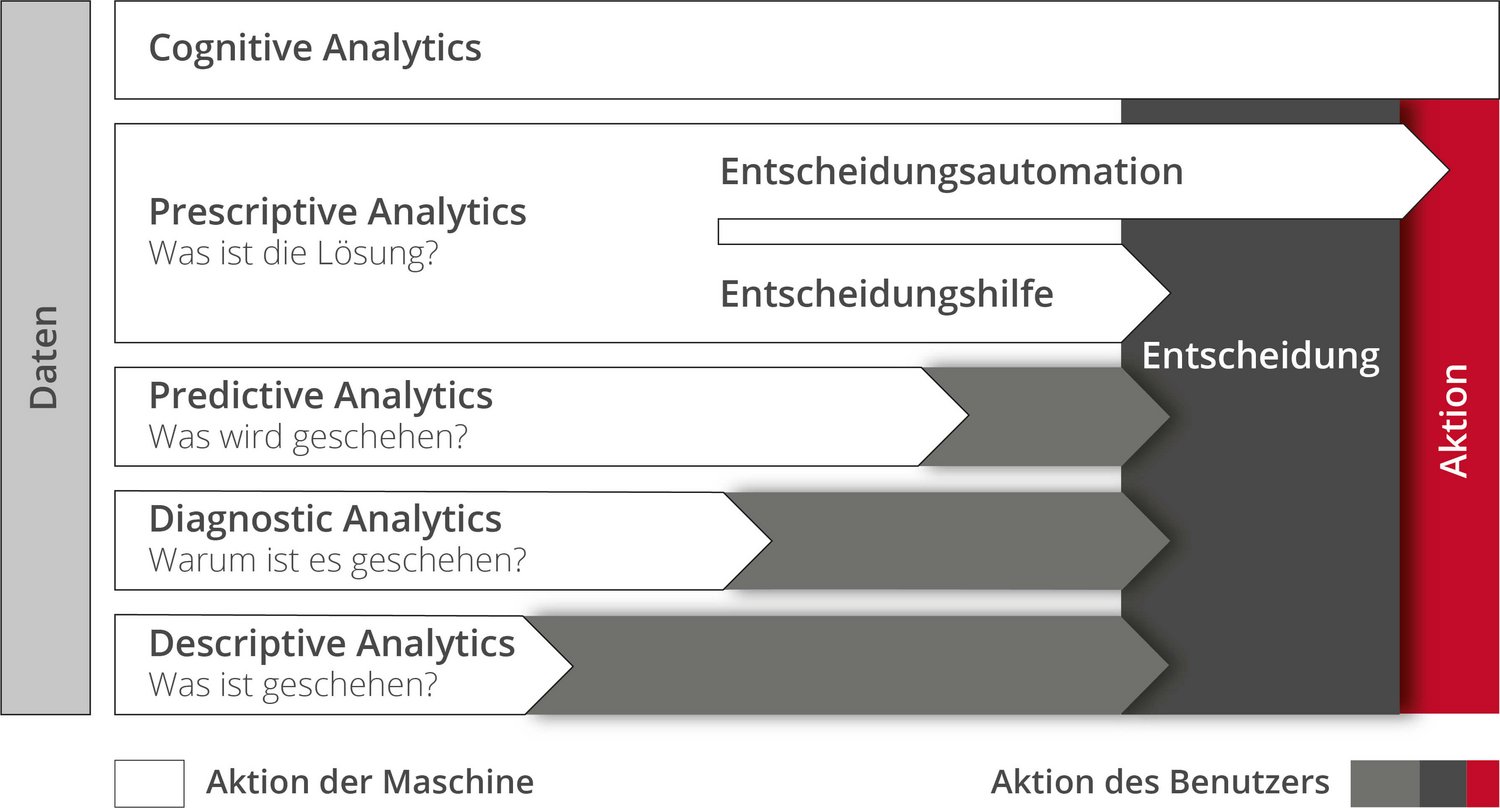
But how does the path from data heap to AI work in practice? "Step by step," is Frank Müller's answer, "although the big goal always sets the direction." One goal could be, for example, software that predicts the failure of equipment components, orders spare parts automatically and coordinates the deployment of technicians. In the first step, the data scientists deal with a purely descriptive inventory of the available data. Connections between data and an analysis of why an event occurred emerge in the second step. Once the causes are known, data scientists can create models that enable predictions in the third step. This builds on step four, which enables recommendations for action based on the prediction. These recommendations can be automated in the fifth step. For example, the software orders the spare part and informs the service technician. Similarly, an automated estimate is also possible as to whether the technician needs to carry out maintenance at short notice or whether it is sufficient if he carries out the repair in the course of maintenance that is planned anyway in a fortnight. "The beauty of data science projects," says Frank Müller, "is that we can jump in and push projects at any time - no matter what stage they are currently at." This is a plus point that the US Navy also made its own decades ago in its collaboration with Adam Wald. At the time, military experts had fallen for a cognitive bias that statisticians now call survivorship bias. It is still omnipresent today, for example when the existence of old buildings leads us to believe that the quality of construction was comparatively higher in the past. In fact, however, these are merely buildings of high quality or aesthetics, which are less frequently demolished and at the same time more intensively maintained than other buildings from that time that have long since disappeared.
Published in the trade magazine "IT&Procution" - click here for the online edition (PDF - german).