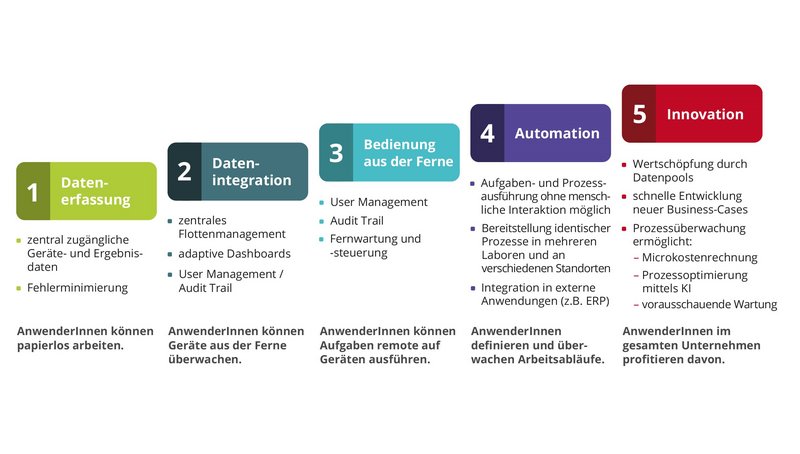
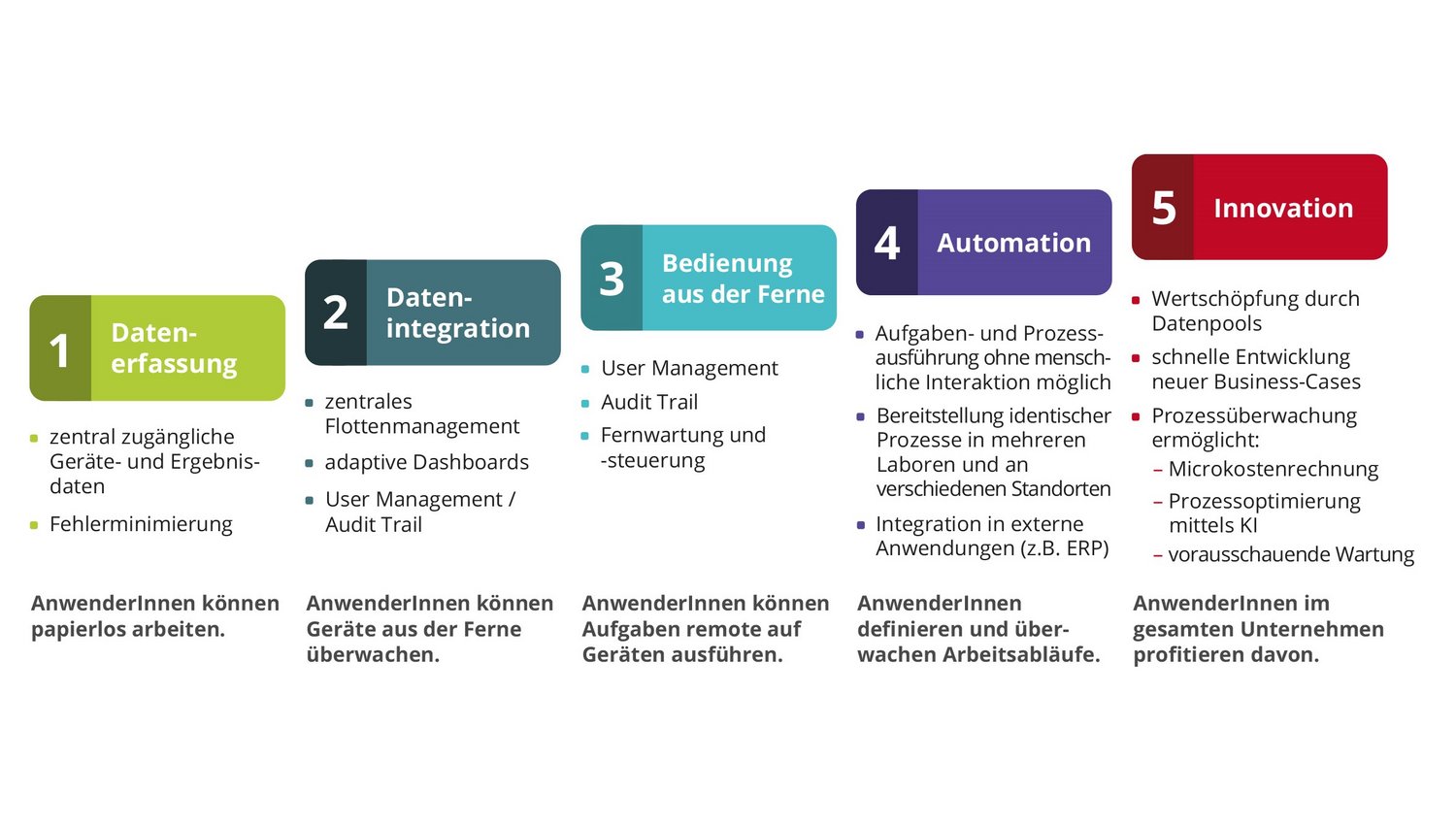
Seit mehreren Jahrzehnten macht es die Industrie allen anderen Branchen vor und zeigt, welche Vorteile und Möglichkeiten die Vernetzung und Digitalisierung von Maschinen, Geräten und Prozessen bietet. In der Laborwelt gewinnt das Vorgehen deshalb ebenfalls zunehmend an Bedeutung, insbesondere weil hier häufig noch manuelle und deshalb fehleranfällige Datentransfers verbreitet sind und mit der Dokumentation eine nicht wertschöpfende Tätigkeit eine wichtige Rolle spielt. Doch lohnen sich die Investitionen in Digitalisierung und Vernetzung überhaupt und welche Möglichkeiten eröffnen sich tatsächlich? Ein Crashkurs in fünf Schritten (siehe Abb. 1) gibt Auskunft.
- Albrecht Liebscher, Key Account Manager Life Science, infoteam Software AG
- Patrick Kraus, Marketing Communications Manager, infoteam Software AG
- Alexander Brendel, Director Life Science, infotem Software AG
Schritt eins: zentrale Verfügbarkeit – die einfachste Form der Datennutzung
Wer nicht das Privileg hat, bereits in einem digitalisierten und vernetzten Labor zu arbeiten, der kennt es aus dem eigenen Alltag: Parameter am Gerät einstellen, Versuchsergebnisse händisch ins Laborbuch abschreiben oder via USB-Stick exportieren und die Daten anschließend am PC wieder eintippen beziehungsweise importieren – wahlweise für die Berechnung weiterer Prozessschritte oder für die Dokumentation. Zwei wesentliche Merkmale charakterisieren dieses Vorgehen: Zeitfresser und Fehlerteufel.
Mit der Vernetzung digitaler Laborgeräte ändert sich das grundlegend. Erstmals stehen die Daten aller vernetzten Geräte zentral zur Verfügung. Das können Parameter des Geräts selbst sein (beispielsweise Betriebsstunden) oder Versuchsparameter (beispielsweise Rührgeschwindigkeit oder Versuchsergebnis). Eine Middleware führt alle Daten an einem Ort zusammen, auf den Mitarbeitende oder Labor-Informations-Management-Systeme (LIMS) direkt Zugriff haben. Middleware beschreibt die verbindende Ebene zwischen Laborgeräten und LIMS/ELN (elektronische Laborbücher). Diese Daten schreibt die Middleware zusammen mit etwaigen Versuchsergebnissen fälschungssicher in die Datenbank und in elektronische Laborbücher (ELN).
Hier laufen alle Daten zentral zusammen. Höhere Ausbaustufen einer Middleware verarbeiten die Daten zudem weiter, sodass zwar alle Rohdaten in einem sogenannten Data Warehouse strukturiert abgespeichert sind, aber nur relevante und aufbereitete Daten an Anwenderinnen und Anwender oder höhere IT-Systeme (z. B. LIMS) weitergegeben werden. Wichtig ist, dass all jene Gerätedaten digital zugänglich sind, die zum Prozess gehören. Nur dann ist die sogenannte „Single Source of Truth“ gegeben, also ein Datensatz, der allein gültig ist (es gibt keine weiteren analogen oder digitalen Datensätze, die zu einer doppelten Datenhaltung führen und deshalb widersprüchlich sein könnten). Labore mit mehreren Prozessen müssen nicht komplett umstellen, sondern können zunächst den wichtigsten Prozess mit dem größten Kosten-Nutzen-Potenzial digitalisieren. Teilweise bringt schon die Gerätevernetzung innerhalb von Teilprozessen nennenswerte Verbesserungen der Arbeitsqualität, -ergebnisse und -geschwindigkeit – weshalb auch eine kleinschrittige, stufenweise Finanzierung solcher Digitalisierungsprojekte möglich ist.
Labormitarbeitende können die ursprünglich autark vorliegenden Daten nun erstmals zentral abrufen und weiternutzen, ohne selbst im Labor zu sein. Sie können den Betriebsstatus von Geräten einsehen oder Versuchs- und Geräteparameter kopieren und für weiterführende Berechnungen oder für Dokumentationen verwenden. Insbesondere für Letztere ergibt sich so ein papierloses Labor. Zwar liegen nun alle benötigten Daten vor, jedoch müssen die Anwenderinnen und Anwender die Daten weiterhin selbst heraussuchen.
Schritt zwei: unidirektionale Kommunikation zum Benutzer – das Labor meldet sich
Wer nicht gerne in großen Datenpools nach den richtigen Daten sucht, bevorzugt vermutlich zeitsparende Übersichten mit den relevanten Infos – sogenannte Dashboards. Beispiel: Welches Gerät ist derzeit in Betrieb? Vor der Vernetzung mussten Laborverantwortliche hierfür ins Labor gehen. Mit der Vernetzung der Geräte in Schritt eins können die Mitarbeitenden den Betriebszustand im Datenpool heraussuchen. Mit einem Dashboard übernimmt die Middleware die Suche nach den Daten und zeigt die Parameter individualisierbar an. Dashboards dienen demnach unterschiedlichen Personen und Gruppen dafür, schnell an relevante Informationen zu gelangen. In vielen Fällen bereitet die Middleware die Rohdaten hierfür erst noch auf. Sie berechnet beispielsweise aus den sekündlich gesendeten Temperaturdaten eines Thermometers den Mittelwert, da dieser für die Nutzerinnen und Nutzer eine höhere Aussagekraft hat als sekündlich schwankende Werte.
User-zentrierte Dashboards benötigen ein User Management, sodass die Middleware weiß, welche Person welches Dashboard und welche Funktionen benötigt. Mit dem User Management entsteht zudem die Möglichkeit für einen Audit Trail (also die digitale Überwachung und Dokumentation, welche Person welche Parameter aufgerufen und geändert hat, welche Befehle sie dem System erteilt hat oder wer wann welche Fehlermeldung erhalten und quittiert hat). Ein kombiniertes Berechtigungsmanagement beschränkt zudem auf Wunsch den Zugriff auf Daten und gibt ausgewählte Inhalte nur für bestimmte Personen(-gruppen) frei.
Gleichzeitig resultiert aus den nun aufbereiteten und einzelnen Personengruppen zugeordneten Daten die Möglichkeit, dass die Middleware aktiv Fehlerzustände erkennt und dokumentiert (Logging) sowie Informationen an die relevanten Personen verschickt (Messaging) – beispielsweise Mitteilungen zu Fehlermeldungen und Alarmen (Temperatur im Kühlschrank über kritischem Wert) oder wenn Arbeitsschritte abgeschlossen sind. Diese Nachrichten kann das System grundsätzlich an alle Arten von Endgeräten weltweit schicken, also auf Wunsch auch an Smartphones. Laborverantwortliche müssen somit nicht mehr vor Ort im Labor sein, sondern das Gerät informiert sie. Um Vorgänge manuell zu stoppen oder auszulösen, ist jedoch weiterhin die Anwesenheit vor Ort erforderlich.
Schritt drei: bidirektionale Kommunikation – Gerätesteuerung aus der Ferne
Wer Arbeitsschritte remote starten oder stoppen oder Geräteparameter aus der Ferne konfigurieren möchte, benötigt anstelle der bisherigen unidirektionalen Kommunikation eine bidirektionale. Labormitarbeitende können so über entsprechende Dashboards Befehle an Laborgeräte senden, beispielsweise einen Rührer mit definierter Rührgeschwindigkeit und -dauer starten. Spätestens jetzt benötigt das System den in Schritt zwei bereits erwähnten Audit Trail, um normenkonform zu dokumentieren, welche Person wann und mit welchen Parametern welchen Prozess gestartet hat. Diese Daten schreibt die Middleware zusammen mit etwaigen Versuchsergebnissen fälschungssicher in die Datenbank und in elektronische Laborbücher (ELN).
Schritt vier: Prozesse werden digital
Während in den Schritten eins bis drei vernetzte Laborgeräte für Einzelkommunikation im Fokus standen, betrachtet Schritt vier die Prozesse (zum Beispiel Standard Operating Procedures: SOP) – oder ein Beispiel für Musikschaffende: Bis jetzt waren es Einzelproben, ab sofort probt das gesamte Orchester.
Prozesse beschreiben die Interaktion zwischen Mitarbeitenden, Geräten und Software eines kompletten Arbeitsablaufs. Mitunter überschneiden sich Prozesse, indem sie auf dieselben Geräte zugreifen. Prozessdaten liegen dann vor, wenn der Datenfluss des gesamten Arbeitsablaufs (Workflow) digitalisiert abgelegt wird. Es existieren also nicht nur einzelne Datenpunkte (beispielsweise nur das Versuchsergebnis), sondern für jeden Zeitpunkt alle relevanten Datenpunkte. Neben der realen Welt entsteht so eine digitale Kopie – der sogenannte digitale Zwilling.
Für digitale Zwillinge ist ein hohes Maß an Automatisierung hilfreich und bisweilen auch notwendig, um alle relevanten Daten digital verfügbar zu haben. Welche Parameter das sind, ist von Prozess zu Prozess unterschiedlich. In den meisten Fällen müssen hierfür auch Systeme und Software in die Middleware eingebunden und vernetzt sein, die bislang losgelöst voneinander agierten. Durch den hohen Grad der Vernetzung und Automatisierung ergibt sich eine Skalierbarkeit des Prozesses, denn ob das System die Arbeitsschritte ein- oder parallel zehnmal durchführt, ist lediglich eine Frage der verfügbaren Hardwarekomponenten. Menschliche Mitarbeitende werden dadurch keinesfalls arbeitslos. Anstatt manuellen Routinearbeiten nachzugehen, stehen sie für höherwertige Aufgaben zur Verfügung und nutzen ebenfalls die Prozessdaten: So können sie im Arbeitsalltag beispielsweise schlussfolgern, dass 20 Prozent der Proben unbrauchbar sind, weil die Temperatur in einem Kühlschrank für eine bestimmte Dauer um einen bestimmten Wert zu hoch war. Auch für das Management halten Prozessdaten Hinweise bereit, etwa wo es einen organisatorischen Flaschenhals gibt und ob eine Optimierung rentabel ist.
Sobald Arbeitsabläufe durchgängig digitalisiert sind, steht erstmals auch ein Softwaremodul zur Verfügung, das anhand der durchzuführenden Arbeiten die ideale Reihenfolge vorgibt und weiß, wann wo welches Gerät frei ist oder benötigt wird (ggf. auch mit sich überkreuzenden Prozessen) – sogenannte Scheduler.
Schritt fünf: KI – das Labor denkt mit
Bereits in den Schritten eins bis drei entstehen große Datenpools (Data Lakes), die je nach Anforderung den Einsatz von statistischen Verfahren oder Systemen künstlicher Intelligenz (KI) zulassen. Die vorliegenden Prozessdaten aus Schritt vier komplettieren die Data Lakes. In ihnen kann KI Zusammenhänge (Korrelationen) aufspüren, die für menschliche Experten entweder zu komplex sind oder so umfangreich, dass die Berechnung Jahrzehnte dauern würde. Die Erfahrung aus der Praxis zeigt, dass eine wahllose Suche in den Daten durchaus wertvolle Erkenntnisse hervorbringen kann, die Wahrscheinlichkeit hierfür aber einem Glücksspiel entspricht. Deutlich zielführender ist es, konkrete Fragestellungen von der KI untersuchen zu lassen oder der KI anhand der Daten Wissen anzutrainieren, sodass sie Entscheidungen selbst trifft oder Empfehlungen gibt. So sagt sie beispielsweise den Ausfall von Geräten voraus, schlägt Formulierungen für die Dokumentation vor oder erkennt Bildmuster automatisiert und ruft nur dann menschliche Experten hinzu, wenn die Daten nicht eindeutig sind.
Für all jene, die bereits mit dem Training und dem Einsatz einer KI für eine konkrete Fragestellung oder Aufgabe liebäugeln und nun befürchten, dass sie erst die Schritte eins bis vier durchlaufen müssen: Es gibt durchaus die Möglichkeit, einen Data Lake speziell für diese eine Anwendung aufzubauen und gegebenenfalls hierfür eine Einzelautomatisierung für die Datenerhebung zu bauen. Sobald jedoch Betriebs- und Gerätedaten global notwendig sind oder ganze Prozesse in die Analyse einfließen sollen, braucht es die Schritte eins bis vier.
Erschienen in der GIT Labor-Fachzeitschrift - hier geht´s zum Artikel.