Abseits des Hypes um Quantencomputing ist dieses noch relativ junge Tätigkeitsfeld auf dem Weg vom Lösen kleinerer, bewusst konstruierter Probleme hin zu praktischer Relevanz im industriellen Umfeld. Wenn Medien in diesem Zusammenhang auf den Aspekt der Quantenüberlegenheit und damit einhergehend auf den exponentiellen Performancegewinn bei einigen Arten von Problemen hinweisen – wobei das Schlagwort „Quantum Machine Learning“ (QML) eine wichtige Rolle spielt –, vergessen sie jedoch, neben der Anwendbarkeit auch auf andere Aspekte wie z. B. Cybersecurity und die damit verbundene Frage nach der Vertraulichkeit, Integrität und Verfügbarkeit der Daten und Modelle einzugehen.
Genau das bildet den Schwerpunkt dieses Artikels. Einleitend stellt der Beitrag das Tätigkeitsfeld des Quantencomputings, den QML-Lebenszyklus und insbesondere dessen Unterschiede zum konventionellen Lebenszyklus im Bereich des maschinellen Lernens vor. Im nächsten Schritt werden die einzelnen Phasen des Entwicklungszyklus in Bezug auf die relevanten CIA-Kriterien geprüft und auf die verschiedenen Bedrohungsszenarien wie auch auf schon heute existierende Gegenmaßnahmen thematisiert. Abschließend betrachtet der Artikel den Stand der Forschung und beleuchtet, bei welchen Fragen in Bezug auf Cybersecurity noch Potenzial für die zukünftige Forschung besteht. Der Artikel beschäftigt sich mit den zurzeit verfügbaren NISQ-Geräten und insoweit ausschließlich mit den gatterbasierten Quantencomputern.
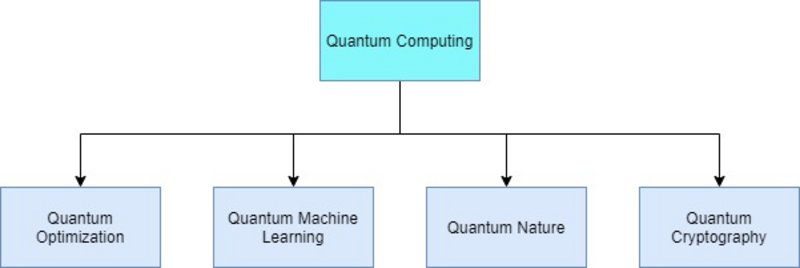
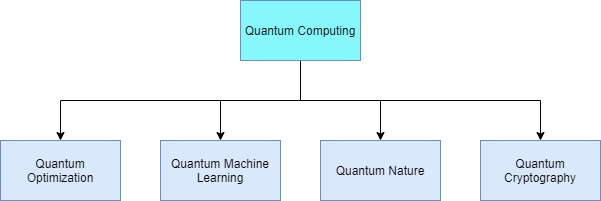
Die Aussage, das relativ junge Feld des Quantencomputings werde irgendwann zu einer Art „Super“-Supercomputer führen, findet sich häufig in den über diese Thematik berichtenden Medien. Quantencomputing soll es ermöglichen, Simulationen von Materialien und Molekülen oder Berechnungen und mathematische Optimierungen um Größenordnungen schneller als auf heutigen Supercomputern auszuführen. Auch heißt es, mittels Quantentechnik solle es alsbald möglich sein, die aktuellen Verschlüsselungsverfahren zu knacken. Quantencomputer können darüber hinaus auch im Bereich des Machine Learning (ML) Anwendung finden und so zu besseren Klassifikationen oder Modellen führen. Die Einteilung in die verschiedenen Aufgabengebiete veranschaulicht Abbildung 1.
1. Aber was sind Quantencomputer eigentlich?
Eine Abgrenzung hat Maußner (2023) [1] vorgenommen: Quantencomputer zeichnen sich dadurch aus, dass ein Qubit als kleinste Rechen- und Informationseinheit eines Quantencomputers nicht – wie ein herkömmliches Bit – nur den Zustand 0 oder 1 annehmen kann, sondern einen beliebigen Zustand dazwischen (Zustandsüberlagerung; Superposition). Qubits können zudem miteinander verschränkt werden, sodass deren Zustand korreliert, d. h., die Zustandsänderung eines Qubits hat unmittelbar eine Auswirkung auf den Zustand eines oder mehrerer anderer Qubits. Derzeit ist nur eine beschränkte Anzahl an Qubits physikalisch realisierbar, und die bestehenden Systeme sind sehr fehlerträchtig und anfällig für Umgebungsrauschen, d.h., jeder Algorithmus ist in der Ausführungszeit – wegen der Dekohärenzzeit – und Komplexität eingeschränkt. Die heute bereits verfügbaren Quantencomputer werden dementsprechend als Noisy-Intermediate-Scale-Quantum-(NISQ-)Geräte bezeichnet.
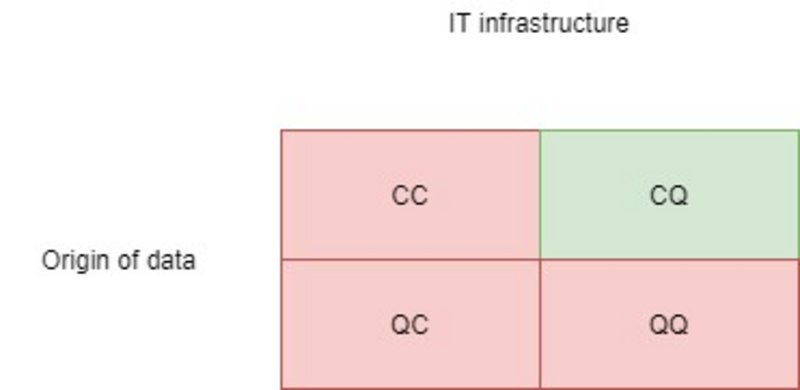
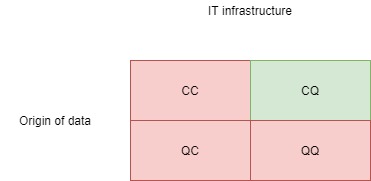
Quantum Machine Learning (QML) als Teilgebiet des Quantencomputings lässt sich laut Hellstern (2023) [2] in vier Bereiche einteilen, gruppiert nach der verwendeten IT-Infrastruktur und der Herkunft der Daten (vgl. Abbildung 2):
- CC: klassische Daten auf konventioneller Hardware
- QC: Quantendaten auf konventioneller Hardware
- CQ: klassische Daten auf Quantenrechnern
- QQ: Quantendaten auf Quantenrechnern
Der Artikel beschränkt sich auf die Gruppe CQ (klassische Daten auf Quantenrechnern), da diese Gruppe heute schon im kleinen Rahmen realisierbar ist.
2. QML-Lebenszyklus
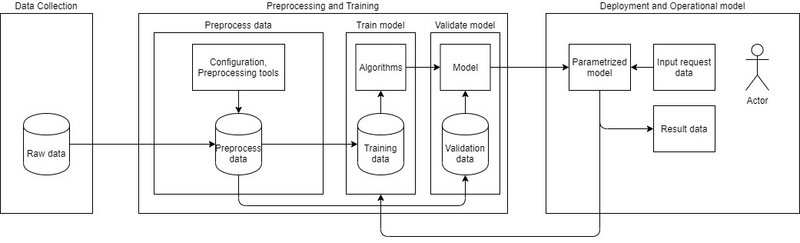
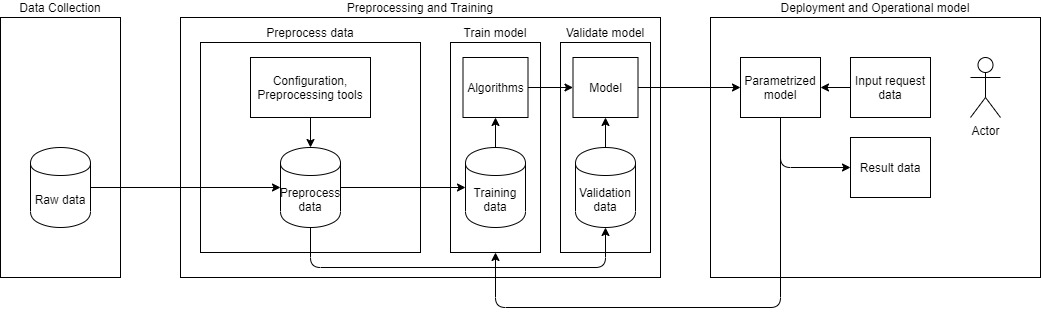
Abbildung 3 zeigt die Phasen des Lebenszyklus klassischer ML-Projekte laut Kempka und Schaad (2022) [3]. Der Zyklus beginnt mit der Sammlung aller benötigten Daten, die man klassifizieren oder bearbeiten möchte. Diese Rohdaten werden in der Phase „Preprocess data“ vorverarbeitet, z. B. indem die Größe von Bildern angepasst wird oder nicht valide Eingabewerte und nicht benötigte Attribute in den Daten entfernt werden.
Danach erfolgt eine Einteilung der Eingabedaten in Trainings- und Validierungsdaten. Während die Trainingsdaten dem Trainieren des Modells dienen, werden die Validierungsdaten verwendet, um die vorausgesagten Werte des Modells mit den erwarteten Werten abzugleichen. Die Werte für Score und Accuracy werden berechnet. Ist die Aussagekraft des Modells nach der Validierung von hinreichender Güte, wird das Modell an die Anwendung oder den Benutzer ausgeliefert. Für einen möglichen weiteren Trainingslauf werden die Benutzerdaten zurückgespielt und die Trainingsphase beginnt erneut.
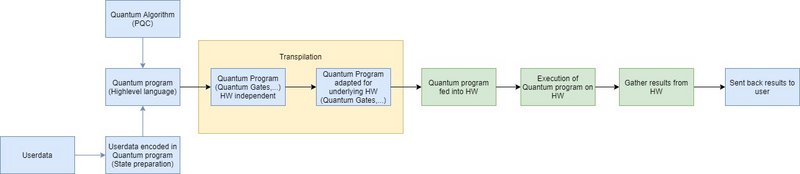
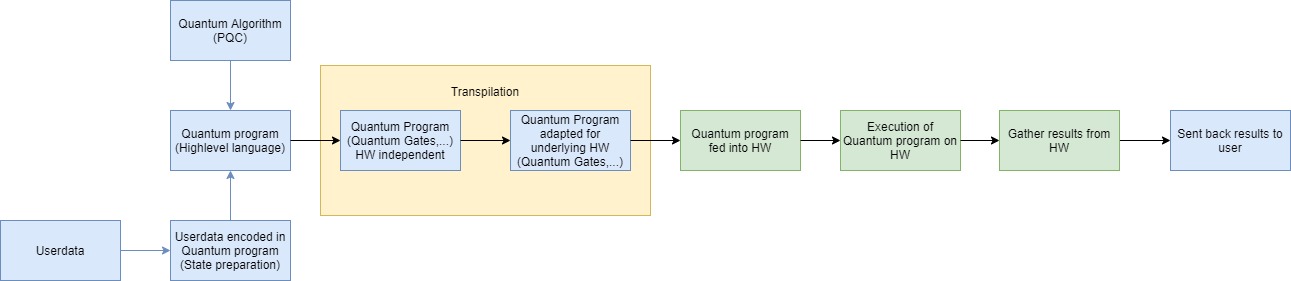
Der obige Lebenszyklus wird in Anlehnung an den Quantensoftware-Lebenszyklus aus Weder et al. (2020)[4] für QML angepasst, indem die Trainingsphase um einen Schritt erweitert wird: die Transformation der Benutzerdaten in ein Quantenprogramm (vgl. Abbildung 4). Nach Weigold et al. (2020) [5] lassen sich hierzu verschiedene Algorithmen als Grundlage für Initialschaltkreise verwenden, unter anderem Basis- und Amplitudenkodierung. Diese Quantenschaltkreise werden dann mit dem sogenannten Ansatz-Schaltkreis kombiniert, wie er in Schuld et al. (2020) [6] dargestellt ist. Die High-Level-Präsentation des Schaltkreises mit allgemeinen Standardgattern wird als Eingabe für die „Transpilationsphase“ (Qiskit Development Team, 2023) [7] benutzt. Dort werden die allgemeinen Gatter und Instruktionen auf die Menge der Gatter und Instruktionen der Zielhardware adaptiert. Hierfür wird auf die sogenannte „Coupling Map“ zurückgegriffen, die die physischen Verbindungen der Qubits untereinander repräsentiert. Um das ursprüngliche Layout auf das Ziellayout anzupassen, werden Verschränkungs- und Swapping-Mechanismen angewandt. Danach kann das erhaltene Quantenprogramm auf die Zielhardware gespielt und ausgeführt werden, um die erhaltenen Ergebnisse zu sammeln und an den Benutzer zurückzusenden.
3. Bedrohungsszenarien
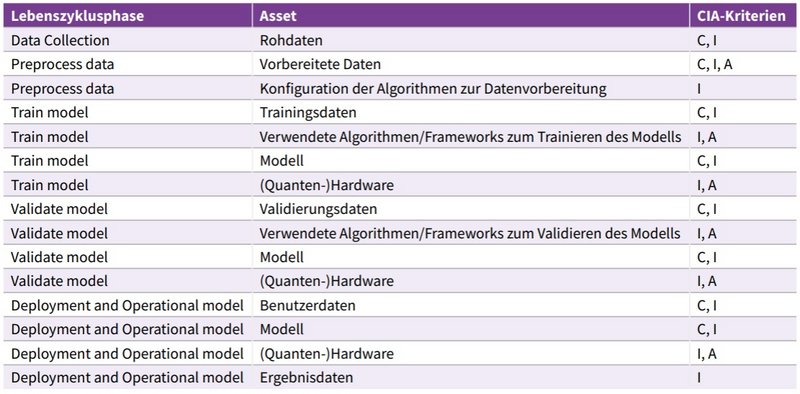
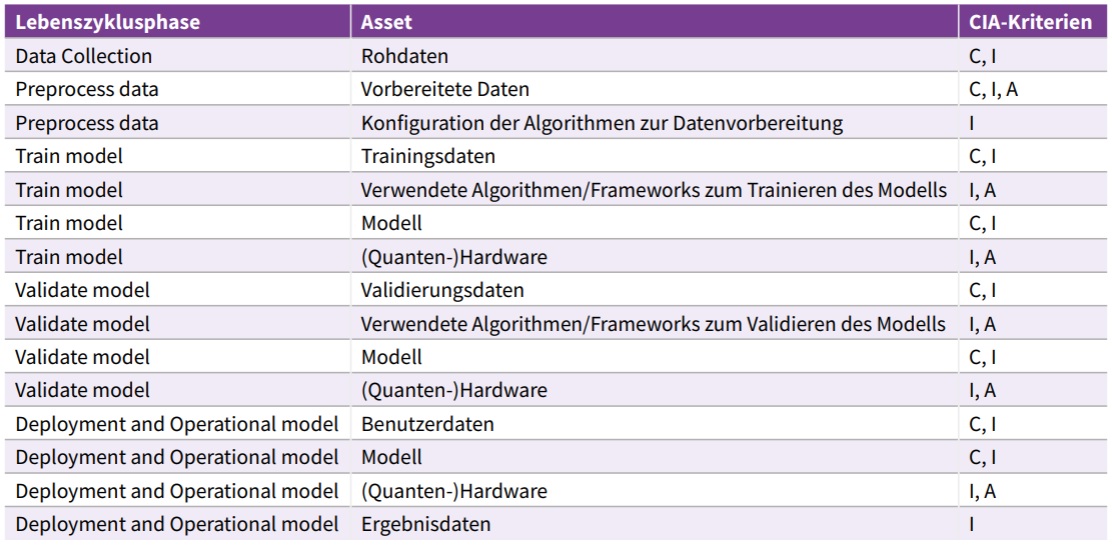
Mögliche Bedrohungsszenarien mit Assets und CIA-Kriterien (Confidentiality/Vertraulichkeit, Integrity/Integrität, Availability/Verfügbarkeit), gegliedert in die Lebenszyklusphasen, sind in Abbildung 7 dargestellt. Die Tabelle ist so fast vollständig auch auf die Phasen im klassischen ML anwendbar. Nachfolgend werden einige Bedrohungsszenarien für die Assets der einzelnen Phasen genauer vorgestellt.
In der Phase „Data Collection“ können über einen „Stealthy Channel“-Angriff gefälschte oder fehlerhafte Daten in die Datensammlung eingeschleust werden, um so deren Integrität zu kompromittieren (vgl. Bundesamt für Sicherheit in der Informationstechnik, 2022) [8]. Die Vertraulichkeit kann verletzt werden, wenn auf den Kanälen, die für die Datensammung genutzt werden, Angreifer mitlauschen. Kritisch ist dies vor allem bei medizinischen Patientendaten oder bei Daten, die spezielle Charakteristiken aufweisen, z. B. Industriedaten.
Erhält ein Angreifer Zugriff auf die verwendeten Algorithmen für die Vorverarbeitung der Daten, kann er diese ändern und manipulieren. Beispielsweise kann er die Trainings- und Validierungsdaten dahingehend modifizieren, dass das Modell falsche Features lernt. Oder er kann die Vorverarbeitungsdauer dahingehend ändern, dass die Verfügbarkeit eingeschränkt wird. Wenn er die verwendeten Algorithmen und Frameworks kennt, kann ein Angreifer die Daten dahingehend abwandeln, dass nach der Vorverarbeitung andere oder versteckte Daten enthalten sind. Dies wird in Chen et al. (2019) [9] näher erläutert.
Beim Trainieren des Modells ergeben sich folgende mögliche Szenarien: Angreifer können „adversarial“ Angriffe auf die Trainingsdaten durchführen und sie verändern (vgl. näher Sultanow et al., 2022 [10]). Weiterhin ist es möglich, beim Zugriff auf das System, auf dem das Training läuft, die Trainingsdaten auszuspähen, um die Vertraulichkeit zu kompromittieren (z. B. medizinische Patientendaten). Des Weiteren kann ein Angreifer die Konfiguration der Trainingsalgorithmen ändern und so z. B. DoS- (Denial-of-Service-)Angriffe provozieren, um damit die Verfügbarkeit des Systems einzuschränken. Hat ein Angreifer direkten Zugriff auf das Trainingssystem, kann er unmittelbar das verwendete Modell ändern, um das System dazu zu bringen, nur Teilaspekte oder fehlerhafte Features zu lernen, z. B. kann er „falsch-positive“ Ergebnisse oder Bias in den Daten erzeugen. Außerdem ist es möglich, das komplette Modell zu stehlen, um mit ihm fehlerhafte Nutzerdaten zu erzeugen. Dies ist sowohl bei QML als auch im klassischen ML zentraler Gegenstand heutiger Forschung. Ein Angreifer kann auch die in der Trainingsphase verwendete Quantenhardware attackieren, um so Wissen über das Modell zu erlangen oder dessen Integrität zu kompromittieren. Auch die erhaltenen Quantenergebnisse können mittels Anpassungen an den Fehlerraten oder dem durch Crosstalk erzeugten Rauschen beeinflusst werden, um, wie in Kundu und Ghosh (2022) [11] beschrieben, „falsch-positive“ Ergebnisse in das Modell zu bringen. Ähnliche Angriffe sind auch in der Validierungsphase des Modells möglich. Daher wird an dieser Stelle nicht noch einmal näher darauf eingegangen. Bei der Auslieferung und im Betrieb ist das Modell dem Risiko eines „Model stealing“-Angriffs ausgesetzt. Mit dem Zugriff auf das Modell können fehlerhafte und manipulierte Benutzerdaten erzeugt werden, die dann als Trainingsdaten für eine erneute Trainingsphase verwendet werden könnten. Angreifer können aus dem System der Benutzer auch die Eingabedaten auslesen und so die Vertraulichkeit verletzen, sollten die Daten nicht vorverarbeitet oder anonymisiert sein. Die Verfügbarkeit kann durch die Betriebszeiten der Quantendienste von den verschiedenen Anbietern limitiert werden. Sollte keine dedizierte Hardware verfügbar sein, kann ein Angriff auf die Job-Warteschlange mit Fake-Jobs zu einer DoS-Attacke führen. Außerdem können die Nutzerdaten verändert werden, sodass sie zu anderen, fehlerhaften Ergebnissen führen. Abschließend kann ein Angreifer auch direkt die Ergebnisse auf dem Benutzersystem manipulieren, um so deren Integrität zu kompromittieren.
4. Gegenmaßnahmen
Nachfolgend werden einige gängige Gegenmaßnahmen für die Bedrohungsszenarien aus Kapitel 3 beschrieben.
Um einen Angriff in der Vorverarbeitungsphase auszuschließen, kann man auf statistische Methoden zurückgreifen und die Rohdaten mit den vorverarbeiteten Daten vergleichen. Dies ist in Chen et al. (2019) [9] detaillierter ausgeführt. Alternativ kann man dafür Sorge tragen, dass eine Vorverarbeitung überhaupt nicht notwendig ist.
Angriffen auf die Hardware kann man begegnen, indem man dedizierte Hardware des Fraunhofer Instituts in Ehningen oder in Zukunft auch beim DLR oder anderen Einrichtungen nutzt. Des Weiteren bieten manche Quantenhardwareanbieter auch exklusiven Zugriff auf deren Systeme an.
Einige Maßnahmen gegen „adversarial“-Attacken sind in Wiebe und Kumar (2018) [12] näher erläutert. Dort ist auch beschrieben, wie man die Güte der Klassifizierer gegenüber diesen Attacken erhöhen kann. Es ist auch möglich, Werkzeuge als Gegenmaßnahme zu entwickeln, die solche Attacken besser detektieren können. Des Weiteren ist es sinnvoll, eingehend zu untersuchen, welche Daten im Modell genau benutzt werden, um Vorhersagen zu treffen. Diesen Punkt analysieren Ribeiro et al. (2016) [13] für klassisches ML am Beispiel „Wolf vs. Husky“: Überraschenderweise lernt das System keine Attribute von Wolf und Husky, vielmehr ist der Hintergrund der Bilder hauptsächlich für die Ergebnisse ausschlaggebend.
Eine Schutzmaßnahme nach „Model stealing“-Angriffen ist z. B., das Modell in die verschiedenen Teile Zustandsvorbereitung, Ansatz und finaler Parametersatz zu zerlegen. Darüber hinaus
können in den Ansatz auch verschiedene, für die Ergebnisse nicht benötigte Zusatzgatter hinzugefügt werden, um so die eigentliche Funktion zu verschleiern.
Um die Integrität des Modells und seiner Ergebnisse zu schützen, kann man sicherstellen, dass die Hardware vor jeder Ausführung zurückgesetzt wird, um Crosstalk oder beeinflusstes Rauschen zu verhindern. Man kann zusätzlich Noise- und Fehlerminderungsalgorithmen anwenden oder dafür sorgen, dass die vorverarbeiteten Daten, die Trainings- und Validierungsdaten ausschließlich in einer sicheren Firmenumgebung genutzt werden.
Die Vertraulichkeit des Modells oder der Daten lässt sich unter Anwendung gängiger Verschlüsselungsalgorithmen gewährleisten.
In der Auslieferungs- und Betriebsphase kann man dafür sorgen, dass nur gehärtete Benutzersysteme verwendet werden, um Eingabedaten und Ergebnisse zu schützen. Und man sollte auf die Aktualisierung des Modells mit neuen Benutzerdaten verzichten, wenn sie nicht benötigt wird.
5. Herausforderungen/Besonderheiten von QML im Vergleich zu klassischem ML
Besondere Herausforderungen für Security-Betrachtungen ergeben sich im Vergleich QML versus klassisches ML an den Schnittstellen aus Abbildung 5. Beide Welten werden bisher größtenteils separat erforscht. Die zentrale Frage sollte allerdings sein: Was passiert auf dem Weg der Daten vom lokalen Ablageort zur Cloud bzw. dem Quantencomputer und vice versa?
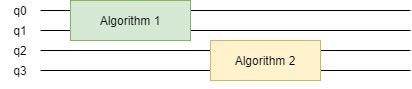
Der momentane Weg im Quantencomputing führt weg vom dedizierten Zugriff hin zur parallelen Ausführung von Algorithmen, um den Durchsatz der Hardware zu maximieren (vgl. Abbildung 6). Es fehlt jedoch die physikalische Trennung, z. B. durch Memory-Protection oder Laufzeitchecks, die aus konventionellen Systemen bekannt sind. Eine weitere Herausforderung ist die Behandlung der Manipulation der Rauschdaten und deren Nachverarbeitung durch Noise- und Fehlerminderungsalgorithmen.
Auch Angriffe auf den Transpiler sind im Quantencomputing denkbar, um so Rückschlüsse auf das Modell zu bekommen oder die Ergebnisse zu manipulieren.
6. Fazit
Bei den im Quantum Machine Learning bestehenden Bedrohungsszenarien besteht der große Vorteil, dass es viele Überdeckungen mit dem Feld des klassischen Machine Learning gibt, die gemeinsam von einer großen Benutzergemeinde erforscht werden können. Es bleiben folglich nur Spezialfälle übrig, mit denen sich die aktuelle Forschung schon intensiv befasst (vgl. Aufteilung der Schaltkreise).
Des Weiteren besitzt Deutschland bereits einen eigenen und von den Herstellersystemen getrennten Quantenrechner in Ehningen. Darüber hinaus bemüht sich die Bundesregierung mit Förderprojekten um den Aufbau weiterer Quantenrechner in Deutschland, um ein Stück unabhängiger von den Global Playern aus den USA oder Kanada zu werden.
Trotz aller Vorsichts- und Gegenmaßnahmen ist für das neue Forschungsfeld des Quantencomputings und des QML nicht ausgeschlossen, dass sich neue oder bisher unentdeckte Angriffe auf die Systeme, Algorithmen und Daten ergeben können.
Erschienen in der aktuellen Ausgabe des atp-Magazins (hier als PDF-Ausgabe erhältlich).
Referenzen
[1] Maußner, M. (2023). Sind Quantencomputer für funktional sichere Produkte einsetzbar? OEM & Lieferant, S. 28–29.
[2] Hellstern, P. D. (2023). Quantenalgorithmen und -implementierung, Teil 2 und 3. HPI.
[3] Kempka, C. D. & Schaad, A. P. (2022). Securing the ML Lifecycle. Industry IoT Consortium.
[4] Weder, B., Barzen, J., Leymann, F., Salm, M. & Vietz, D. (2020). The Quantum software lifecycle. APEQS 2020: Proceedings of the 1st ACM SIGSOFT International Workshop on Architectures and Paradigms for Engineering Quantum Software, S. 2–9.
[5] Weigold, M., Barzen, J., Leymann, F. & Salm, M. (2020). Data encoding patterns for quantum computing. PLoP ‘20: Proceedings of the 27th Conference on Pattern Languages of Programs, S. 1–11.
[6] Schuld, M., Bocharov, A., Svore, K. M. & Wiebe, N. (2020). Circuit-centric quantum classifiers. Phys. Rev. A 101.
[7] Qiskit Development Team. Transpiler (qiskit.transpiler). qiskit.org/documentation/apidoc/transpiler.html, abgerufen am 07.06.2023