Systeme künstlicher Intelligenz (KI) ziehen in die Labore ein? Sie übernehmen lästige Routinearbeiten, unterstützen bei der Qualitätssicherung und entdecken bislang verborgenes Wissen – so die Theorie. Tatsächlich gibt es erst wenige Unternehmen, die KI tatsächlich nutzbringend einsetzen. Der Großteil der Unternehmen müsste dagegen zunächst eine digitalisierte Basis schaffen, um überhaupt die Voraussetzungen für eine erfolgreiche KI-Nutzung zu erfüllen. Bereits ohne KI würde eine Digitalisierung und Vernetzung ein äußerst großes Optimierungspotenzial erschließen.
- Dr. Daniela Franz, Lead Strategy Life Science, infoteam Software AG
- Dr. Stefano Signoriello, Lead Data Scientist, infoteam Software AG
- Patrick Kraus, Marketing Communications Manager, infoteam Software AG
Die unterschiedlichsten Systeme künstlicher Intelligenz sind seit vielen Jahren im Einsatz, und die Anzahl steigt kontinuierlich. Das betrifft nicht nur den privaten Alltag. Längst wurden in vielen Industriezweigen und Unternehmen Einsatzbereiche identifiziert, in denen KI unliebsame Alltagsaufgaben erleichtern, Produktqualität verbessern, neue Serviceangebote erschließen und Entscheidungsfindung unterstützen oder sogar automatisieren kann. Im Laborumfeld sieht die Realität jedoch noch anders aus. Das überrascht auf den ersten Blick, denn grundsätzlich sind die Einsatzmöglichkeiten von KI im Labor ebenso vielseitig und lohnend wie in allen anderen Industriezweigen, die seit einigen Jahren auf KI-Unterstützung setzen.
KI im Labor
Dass der Einsatz von KI im Labor derzeit trotz des großen Potenzials noch so gering ist, hat zwei Hauptgründe: Zum einen erfordert KI digitale Daten – wie sie in zahlreichen Laboren noch nicht vorliegen. Diese benötigen deshalb zunächst eine passende Infrastruktur, um von KI profitieren zu können. Zum anderen erkennen Unternehmen häufig noch nicht, dass der Einsatz von KI ein möglicher Lösungsweg für ein bereits identifiziertes Einzelfallproblem ist. Zudem befürchten viele Laborverantwortliche hohe Entwicklungskosten für eine eigene KI-Lösung mit unklarem Endergebnis. Dem kann in einem strukturiert durchgeführten KI-Projekt durch eine erste Einschätzung begegnet werden.
Vorbereitung: Daten verfügbar machen
Systeme künstlicher Intelligenz benötigen zum Teil große Mengen an digitalen Daten. Bevor sie für die KI-Entwicklung zum Einsatz kommen, bieten sich im Vorfeld bereits erste Datenanalysen an. Diese kommen mit einer geringeren Menge an Daten aus und liefern häufig schon erste Antworten auf die konkrete Fragestellung. Ob Unternehmen diese Daten bereits gesammelt haben oder erst anfangen zu sammeln, hat allenfalls zeitliche Auswirkungen. Mit einem Großteil der verfügbaren Daten trainieren Datenwissenschaftlerinnen und -wissenschaftler (Data Scientists) das KI-Modell. So lernt es, Muster und Zusammenhänge in den Daten zu erkennen, sich dies zu merken und dieses Wissen eigenständig anzuwenden. Je besser die Trainingsdaten, desto besser das Wissen. Der andere Teil der Daten dient als Testumgebung: Die Data Scientists testen mit diesen Daten die Qualität der KI. Eine große Herausforderung im Laborumfeld ist derzeit, Daten zu digitalisieren und mittels durchgängiger Vernetzung verfügbar zu machen. Viele Laborgeräte arbeiten autark, sind weder innerhalb des Labors mit einem LIMS oder einer Middleware verbunden noch über das Internet für die Gerätehersteller erreichbar. Dadurch gehen bleiben derzeit vielerorts gleich drei Chancen ungenutzt:
1. Geräteherstellern fehlen bislang große Datensätze zur Nutzungsform ihrer Geräte (beispielsweise Einsatzzeiten, Temperaturdaten, Energieverlaufsprotokolle, Vibrationsanalysen etc.) und sie können dementsprechend auch keine Serviceleistungen wie Ausfallvorhersagen oder intelligente Wartungsintervalle anbieten.
2. Softwarehersteller für LIMS- und Middleware-Lösungen können zwar KI-Module für generische Vereinfachung im Labor anbieten, es fehlen aber Versuchs- und Prozessdaten aus den Laboren, um die Module mit entsprechenden Daten zu füttern.
3. Die Labore haben das größte Nachsehen. Noch heute werden vielerorts Versuchsdaten per USB-Stick oder sogar händisch in ein LIMS übertragen oder Laborbücher manuell ausgefüllt. Das bedeutet nicht nur einen hohen Zeitfaktor, sondern auch ein Fehlerrisiko. Hinzu kommt, dass Labore derzeit kaum Chancen haben, ihren spezifischen Herausforderungen mit einer eigenen, individuellen KI-Lösung zu begegnen, da große digitale Datensammlungen meist fehlen.
Die Lösung wäre: Digitalisierung und Vernetzung. Dazu gehört insbesondere eine einheitliche Kommunikationsschnittstelle, so dass sämtliche Laborgeräte unterschiedlicher Hersteller und Disziplinen problemlos mit verschiedenen Laborsoftwares verknüpfbar sind. Ein solcher offener und herstellerunabhängiger Standard ist LADS (Laboratory Analytics Device Standard), wie er derzeit entsteht unter Führung des Branchenverbands Spectaris und in Zusammenarbeit mit rund 40 Mitwirkenden aus der weltweiten Laborbranche. Er basiert auf dem OPC-UA-Standard, den produzierende Unternehmen Anfang der 1990er initiiert haben und der inzwischen weltweit der etablierte Standard im Industrieumfeld ist.
Sobald bislang autarke Laborgeräte mit einer Laborsoftware verbunden werden können, öffnet sich für Labore und auch die Hersteller von Laborgeräten und -software ein riesiges Optimierungspotenzial. So könnte eine breite Masse von Laboren ihre Versuchsabläufe, Prozesse und Dokumentation automatisieren. Dadurch sinkt das Fehlerrisiko, im Gegenzug steigt die Flexibilität und ohnehin schon knappe Personalressourcen stehen für wertvollere Aufgaben zur Verfügung, als Daten von einem System in ein anderes System zu übertragen. Und es entsteht damit auch – sozusagen als Nebenprodukt – die Möglichkeit, Daten im großen Stil zu sammeln – die Grundlage für den Einsatz von KI.
Von Daten zum fertigen KI-Tool
Die Entwicklung eines Systems künstlicher Intelligenz ist grundsätzlich unabhängig von der Branche, in der es eingesetzt wird. Data Scientists abstrahieren vom branchenspezifischen Anwendungsfall auf eine datenzentrierte Sichtweise und wählen das passende Modell und geeignete Methoden, um das Modell zu trainieren. Ob eine KI die Ausfallvorhersage für eine Gasturbine oder für einen Pipettierroboter übernehmen soll, ist also für die Entwicklung der KI im Grunde nebensächlich. Häufig sammeln Unternehmen zunächst wahllos Daten und hoffen, „dass man daraus später mal irgendwelches Wissen herausziehen kann“. Tatsächlich ist es möglich zu prüfen, ob statistische Verfahren und neuronale Netze Auffälligkeiten, Muster und Zusammenhänge in diesen Daten finden, die den Verantwortlichen bislang unbekannt waren. Die Erfolgschancen sind jedoch im Vorfeld unklar und die Wirtschaftlichkeit lässt sich erst im Nachhinein beurteilen.
Ideal ist hingegen, wenn in Unternehmen bereits eine konkrete Aufgabenstellung oder ein Problem identifiziert wurde, dessen Lösung das Unternehmen in seiner Entwicklung und Wettbewerbsfähigkeit voranbringen kann. Im Falle eines Geräteherstellers könnten das beispielsweise Geräteausfälle sein, deren Ursache und Früherkennung wichtig ist, um sowohl robustere Geräte zu entwickeln als auch ungeplante Ausfallzeiten der Geräte bei den Kunden minimieren zu können. In Laboren wäre z. B. die Optimierung der Qualitätskontrolle ein möglicher Anlass für das Entwickeln einer KI-Lösung.
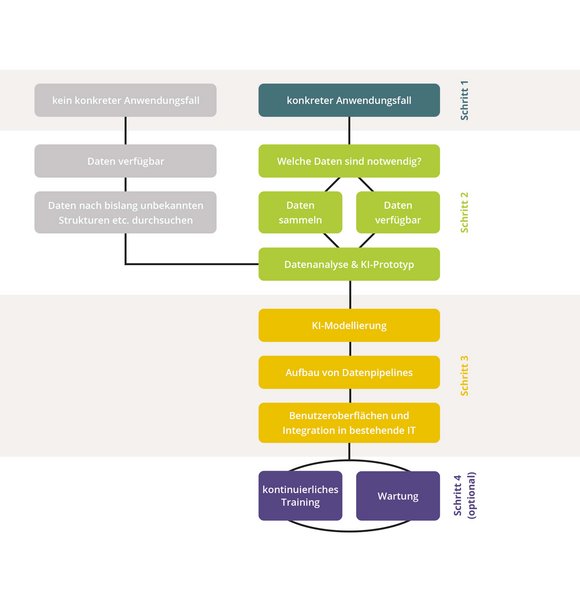
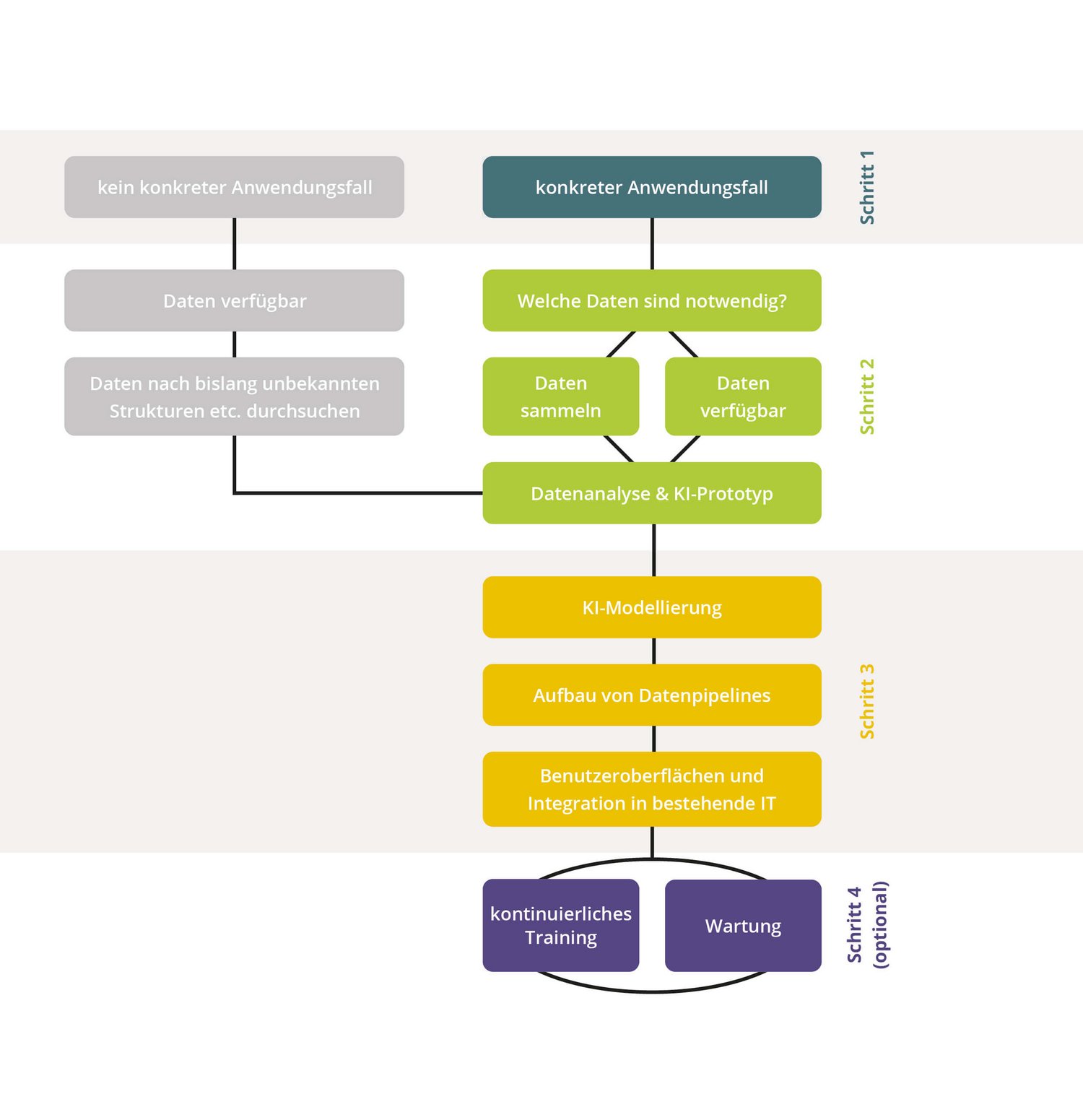
So kann es aussehen: Anhand eines konkreten Anwendungsfalls können die Datenwissenschaftler ein strukturiertes KI-Projekt starten, bei dem auch der Nutzen jederzeit transparent sind: Mit einer Datenexploration klären sie noch vor dem Projektstart, welche Daten notwendig sind, ob bereits verfügbare Daten für den jeweiligen Anwendungsfall passen und in welcher Form die Daten vorliegen müssen. Erst danach entsteht im zweiten Schritt mittels „Rapid Prototyping“ ein erstes KI-Modell, das Aufschluss darüber gibt, ob eine vollumfassende KI-Modellierung überhaupt wirtschaftlich und inhaltlich sinnvoll ist. Wenn ja, entwickeln und trainieren Data Scientists sowie Softwareentwicklerinnen und -entwickler das KI-Modell, bauen Datenpipelines für einen kontinuierlichen Datenfluss im späteren Praxiseinsatz auf, binden die KI in Benutzeroberflächen und bestehende IT-Infrastruktur ein und entwickeln optional Wartungsmechanismen und -routinen.
Massenspektren mit KI beurteilen
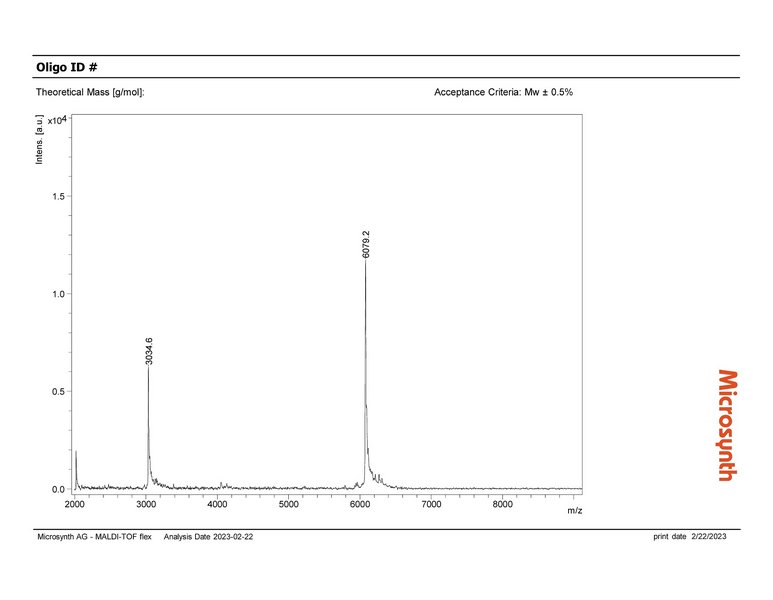
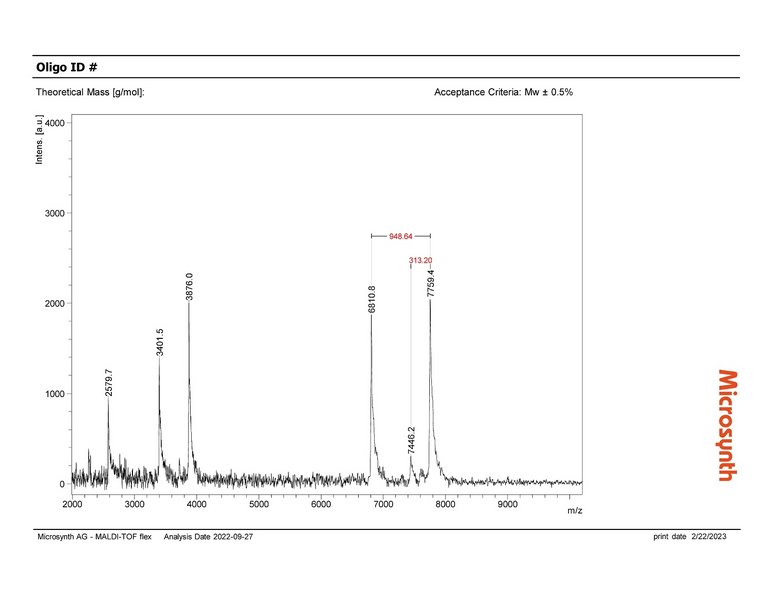
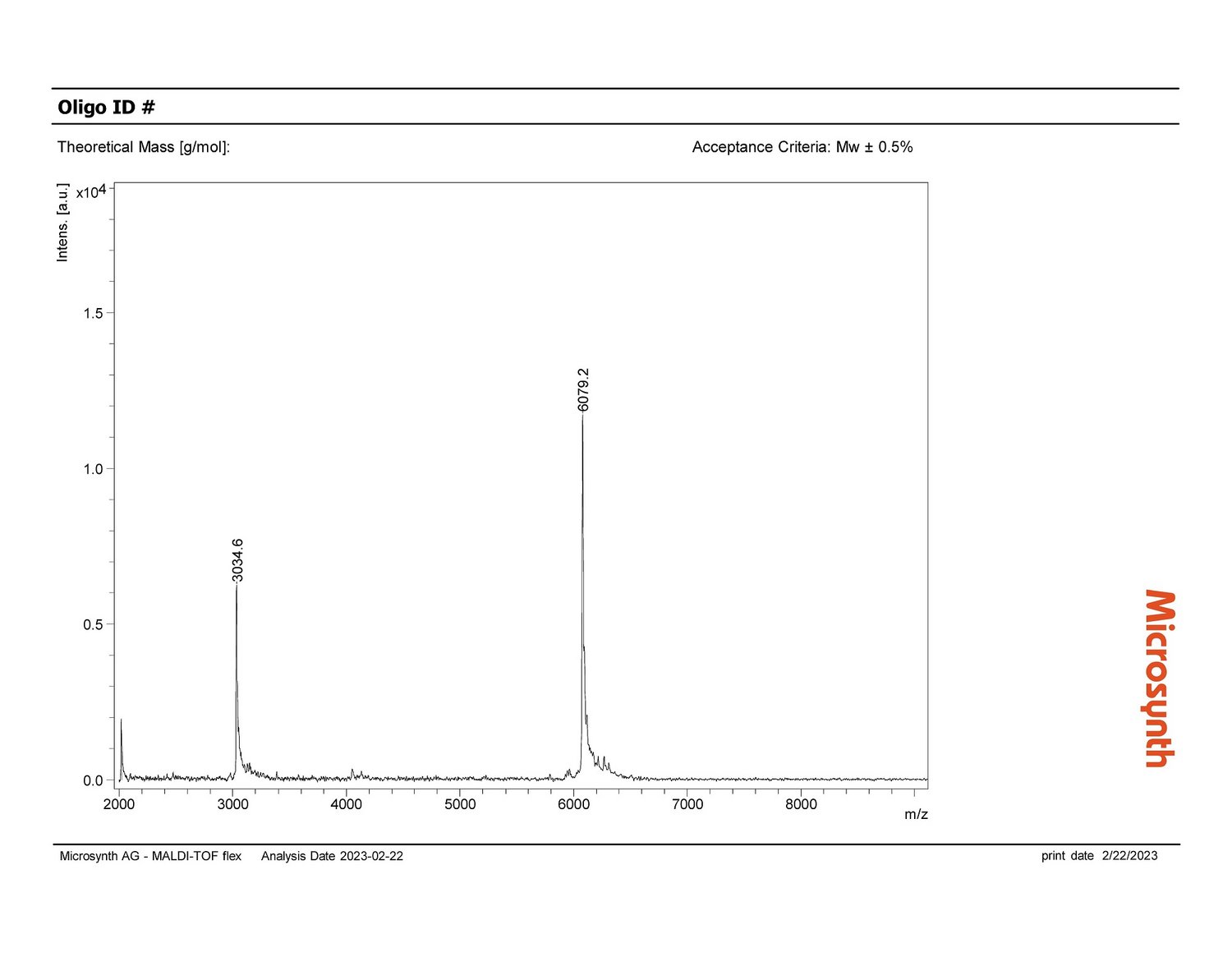
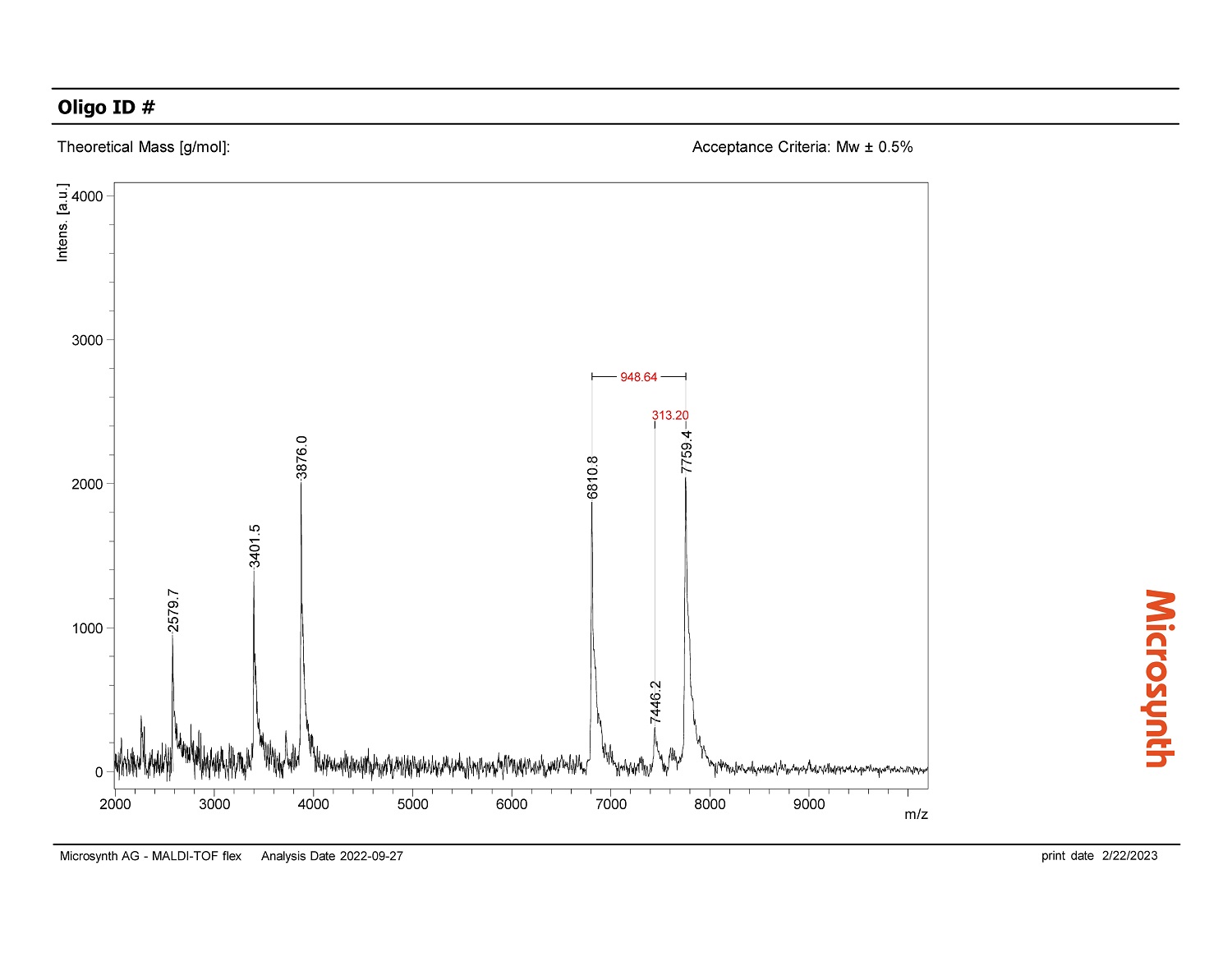
Auch beim Unternehmen Microsynth, wo bald Künstliche Intelligenz in Laboren zum Einsatz kommen soll, durchläuft das KI-Projekt derzeit genau dieses Schema. Die Microsynth AG mit Hauptsitz in Balgach in der Schweiz hat sich auf spezifische DNA- und RNA-Oligonukleotidsynthesen spezialisiert. Bevor die produzierten Oligos an die Kunden gehen, durchlaufen sie eine strenge Qualitätskontrolle: Mittels Massenspektrometrie ermitteln Expertinnen und Experten, ob die produzierten Oligos in ihrer Zusammensetzung den Vorgaben der Auftraggeber entsprechen. Hierfür sichtet eine Person jedes erzeugte Massenspektrum und beurteilt, ob die Peaks dem zu erwartenden Bild entsprechen oder ob es außergewöhnliche Peaks gibt. Bei Microsynth fallen pro Tag bis zu 2 000 Messungen an, die innerhalb weniger Stunden und vor dem Versand der Oligos begutachtet werden müssen – eine wichtige Arbeit, aber auch ein hoher Zeit- und Kostenfaktor. Die Verantwortlichen stellten sich deshalb die Frage, ob eine KI die Qualitätskontrolle unterstützen oder sogar automatisiert übernehmen könnte. Die Idee: Eine KI prüft die Messergebnisse und „holt“ nur dann menschliche Unterstützung zu Hilfe, falls die Kontrolle nicht den Erwartungen entspricht. So würde die KI den Bewertungsprozess beschleunigen, und die menschlichen Expertinnen und Experten hätten mehr Zeit für andere wertschöpfende Arbeiten.
Microsynth hat von den beauftragten Data Scientists ein positives Feedback zur Machbarkeit eines KI-Tools und eine Hausaufgabe bekommen: Es bedarf Daten. Damit die gewünschte KI später die Massenspektren eigenständig beurteilen kann, benötigt sie Spektren verschiedenster Oligos als Datenbasis. So lernt sie, was korrekte Ergebnisse sind und welche Ergebnisse von der Norm abweichen. Die Erstellung der Datenbasis ist zwar mit Arbeit verbunden, zahlt sich aber mit umso präziseren KI-Ergebnissen aus. Naheliegend ist, die Daten der vielen täglichen Messungen nun systematisch zu speichern und mit den Labels „korrektes Spektrum“ oder „auffälliges Spektrum“ zu versehen. Möglicherweise kann aber auch ein von Google entwickeltes KI-Modell zur Vorhersage von Massenspektren unterstützen.
Acht Schritte zu KI im Labor
- Daten verfügbar machen & Digitalisierung, Vernetzung, offene Kommunikationsstandards
- sichere Datenhaltung
- Datenanalyse
- KI-Modellierung & KI-Training & KI-Evaluation
- Aufbau von Datenpipelines
- Entwicklung von Dashboards und Benutzeroberflächen
- Einbindung in bestehende IT-Systeme
- Wartung und Pflege
Praxisbeispiel für KI im Labor
Vorhersage von Ereignissen, Ergebnissen und Wahrscheinlichkeiten – Systeme künstlicher Intelligenz können anhand gespeicherter Daten aus der Vergangenheit (sogenannte historische Daten) lernen, Muster und Zusammenhänge in den Daten zu erkennen. Mit dem erworbenen „Wissen“ können solche Systeme nun Ereignisse, Ergebnisse und Wahrscheinlichkeiten für die Zukunft vorhersagen. Ein Beispiel hierfür ist Predictive Maintenance, also vorausschauende Wartung: Kunden eines Geräteherstellers meldeten immer wieder plötzliche Geräteausfälle. Die betroffenen Geräte konnten so lange nicht genutzt werden, bis ein Techniker vor Ort den Schaden behoben hatte. Die Techniker stellten in allen Fällen die gleiche Ursache fest: Eine stromführende Schraubverbindung lockerte sich aufgrund von Vibrationen sukzessive im laufenden Betrieb, was wiederum zu steigenden Temperaturen an der Verbindung führte. Die Folgen waren Stromunterbrechungen und thermische Schäden im Gerät.
In den Geräten hat der Gerätehersteller bereits eine Vielzahl von Temperatursensoren verbaut. Sie schicken stetig Betriebsdaten von den weltweit im Einsatz befindlichen Geräten an den Gerätehersteller – sowohl in Phasen des störungsfreien Betriebs als auch in Phasen, in denen sich die Schraubverbindung lockert und das Gerät letztlich ausfällt. Anhand der historischen Daten konnten Data Scientists ein System künstlicher Intelligenz trainieren, das die Gerätetemperatur in Abhängigkeit der Nutzungsform für den Normalbetrieb vorhersagt. Diese von der KI vorhergesagte Temperatur vergleicht eine Software mit der tatsächlich gemessenen Temperatur und identifiziert signifikante Abweichungen anhand der Gerätenutzung (und nicht durch Überschreiten eines festgelegten Grenzwerts).
Diese Ausfallvorhersage nutzt der Gerätehersteller, indem er seinen Kunden einen optionalen Wartungsservice für störungsfreien Betrieb anbietet. So schickt er frühzeitig, bevor es zu einem Geräteausfall kommt, seine Techniker zum Kunden, die das Gerät warten und die Schraubverbindung fixieren. Diese Wartung ist für die Gerätenutzer planbar, und dank weniger ungeplanter Ausfälle steigen die Verfügbarkeit und Produktivität der Geräte ebenso wie die Zufriedenheit der Kunden als Gerätenutzer.
Erschienen in "LABO | Fit for Lab" - hier geht´s zur Online-Ausgabe (Seite 16).